
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
1.文章内容总结
1.1 背景和挑战
背景:深度学习的快速发展推进了向微调大型预训练模型转变用于下游任务,而非从头开始训练。初始在大规模数据集上训练过后,预训练模型具备了出色的常识,并能熟练识别和处理大型数据模式。这些模型在下游任务上微调后能获取特定任务的知识。在这种情况下,将多个特定任务的模型merge成一个统一的模型成为了知识转移和多任务学习的有效、可扩展的策略。
动机和挑战:现有的方法主要目的是在原始参数空间中找到一种稳定的多任务最优解决方案。这些方法都没有引进任何新参数,因此都维持了初始的推理成本。然而,随着特定任务的最优解决方案的变化,这种方法对每个实例的独特要求的适应性施加了限制(挑战1)。另一个重要的挑战是减轻不同模型参数之间的冲突,这会大大恶化平均性能(挑战2)。现有的方法尽管在某些场景下有效,但可能不能灵活处理多任务学习的动态性质,最优解决方案可能会因为输入而变化(挑战3)。
为了解决这些挑战,paper提出了一种新的方法来合并视觉Transformers(ViTs),即:WEMoE,这个模块可以基于输入样例动态整合共享知识和特定任务知识,因此可以更灵活的适应每个实例的特定需求。
1.2 WEMoE主要思想
通过识别和分离共享知识和特定任务知识然后动态整合他们可以大大缓解参数冲突问题,利用对所有任务有利的共享知识,同时考虑特定的要求。通过基于特定输入数据动态结合这两种类型的知识,可以创建出一种更灵活更有适应性的模型,这样可以有效的处理更广泛的任务。
1.3 文章工作及横向对比
1.3.1 文章工作
主要贡献:提出了一个新的分离共享知识和特定任务知识的框架,设计了一个新的权重集成的混合专家模型(WEMoE),它可以基于输入样例动态整合共享知识和特定任务知识。
框架概览:如图:
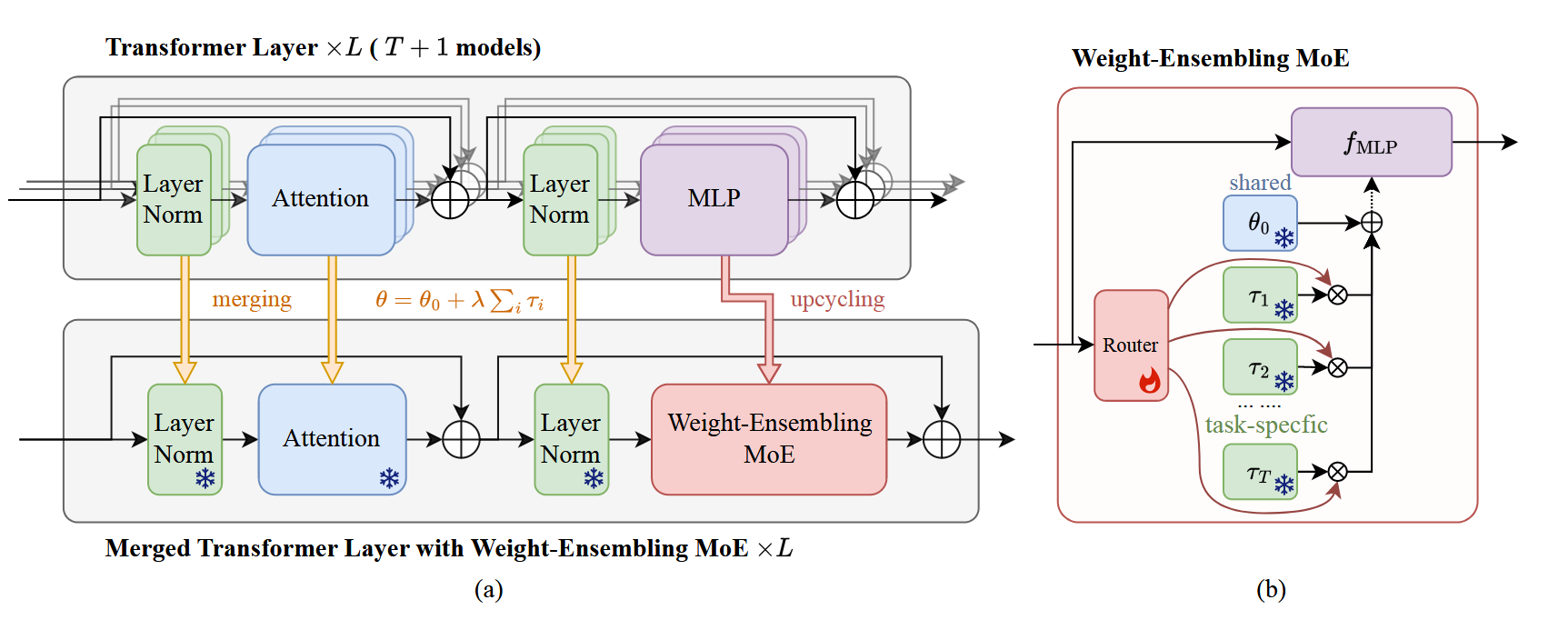
文章设计的这个框架是在有T个Transformer模块的情况下,再加一个模块,其中原先的MLPs被升级成了WEMoE模块;WEMoE的框架在上图b中,输入数据输送到Router后Router会根据输入去选择出对应的task vectors(task vector是通过微调模型权重减去预训练模型权重得到),然后根据公式$ \theta=\theta_0+\lambda \sum_i\tau_i $将task vectors和共享参数$\theta_0$进行计算得到$\theta^{MLP}$。(其中$\lambda$ 在这篇文章里等于0.3)
WEMoE的数学表示:
$$ \begin{equation} \left\{ \begin{aligned} &w=mean(r(h_{1:N}^{in}))\in\mathbb R^{T\times1},\\ &\theta^{MLP}=\theta_0^{MLP}+D_\tau w,\\ &h_{1:N}^{out}=f_{MLP}(h_{1:N}^{in};\theta^{MLP}). \end{aligned} \right. \end{equation} $$$h_{1:N}^{in}$是token的输入序列,$h_{1:N}^{out}$是token的输出序列,$f_{MLP}$是MLP函数,$D_\tau\in \mathbb R^{|\theta^{MLP}|\times T}$(<font color="red">怀疑这里的维度应该是写成$\theta_0^{MLP}\times T$,虽然$\theta$和$\theta_0$维度都一样,但是我认为这里应该协会写成$\theta_0$而不是用该算式得到的结果参数的维度作为维度</font>)一个任务向量的字典矩阵,维度为$\theta_0^{MLP}$的维度*任务向量的个数$T$(所以$w$肯定是要进行维度转换才能和$D_\tau$做矩阵乘法,至于他是在route里用$W2\ or\ W_1$去做的转换还是专门在路由选择结束后专门做的转换估计要看代码才知道);$f_{MLP}$其实就是MLP函数,就是$f(Wx+b)$的一个变换,然后$f()$选择什么激活函数要看下代码才知道。
$r()$是路由的数学表达式,具体如下(分成0层隐藏层和2层隐藏层情况):
$$ \begin{equation} r(h)=W_2ReLU(W_1h+b_1)+b_2,\ l=2, \end{equation} $$$$ \begin{equation} r(h)=b_0,\ l=0 \end{equation} $$$W_1$和$W_2$的初始值通过从均值为0、方差为0.01的高斯分布中采样而得,$l=0$时$b_0$为$\lambda$,$b_1$和$b_2$分别为0和$\lambda$。
1.3.2 方法对比
重新审视模型merge:从多目标优化的角度来看,最优merge模型的解空间是$S$中下游任务的Pareto前沿。文章认为merge多个模型的时候也类似有多个目标,可以用多目标优化的思想去考虑merge模型,使得merge的模型性能综合达到最优。随着解空间越来越大、越来越复杂,找到最优merge模型是很有挑战性的。此外,我们无法获得下游任务的训练数据,只有预训练模型和微调好的模型,这使得我们无法像传统的多任务学习环境一样从头开始训练一个模型。因此,我们需要找到一种方式,将预训练模型和微调模型的知识转移到一个统一的merge模型中。
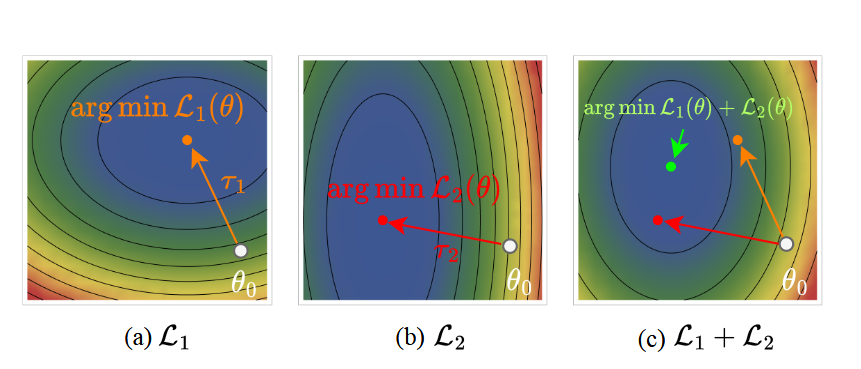
此外,文章用了损失地貌的图来对比解释Pareto最优,没有静态解$\theta^\prime$能同时最小化所有任务的损失好过$arg\ min_\theta\ \mathcal L_1(\theta)+\mathcal L_2(\theta)$:
1.3.2.1 实验数据平均性能对比
WEMoE的平均性能超过传统的MTL基线0.5%和0.1%(即$Tab.2$和$Tab.3$的结论,$Tab.2$中WEMoE平均准确率是89.4%,比TRADITIONAL MTL88.9%高0.5%,$Tab.3$中WEMoE是93.6%,比TRADITIONAL MTL93.5%高0.1%),表中可以看出比起其他merge方法平均性能也更好。
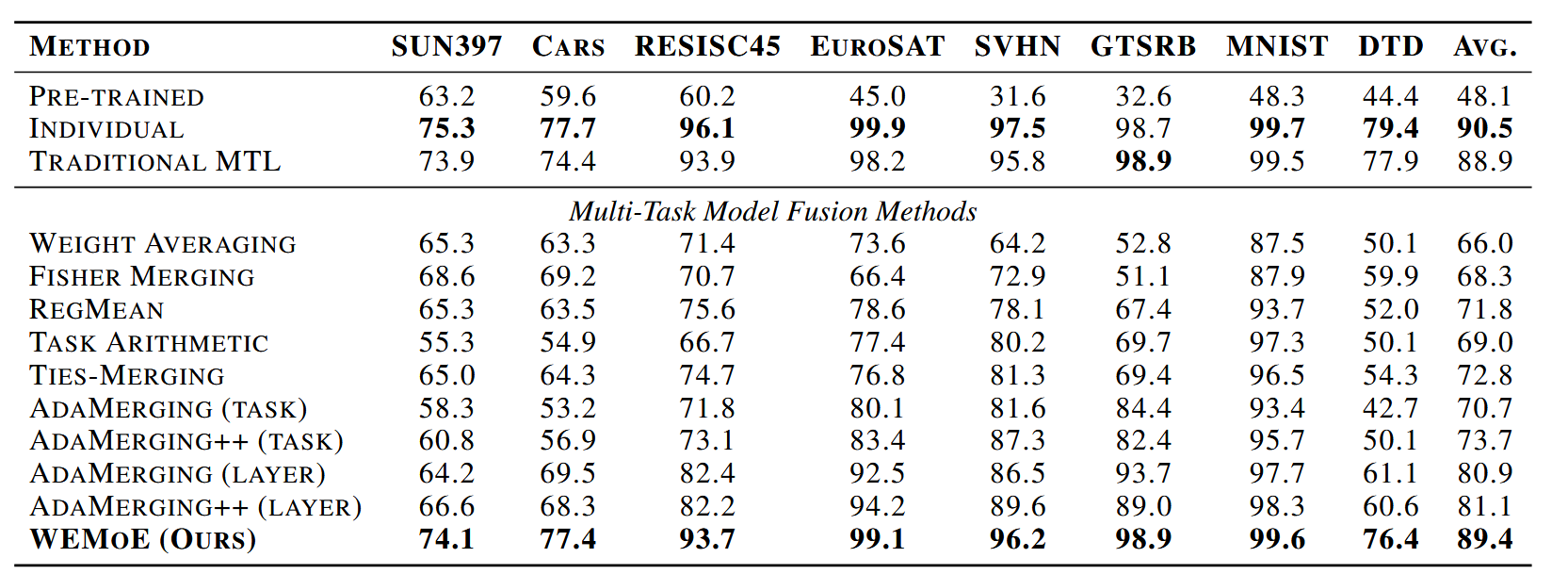
Tab.2:在8个任务上merge CLIP-ViT-B/32模型时的多任务性能。
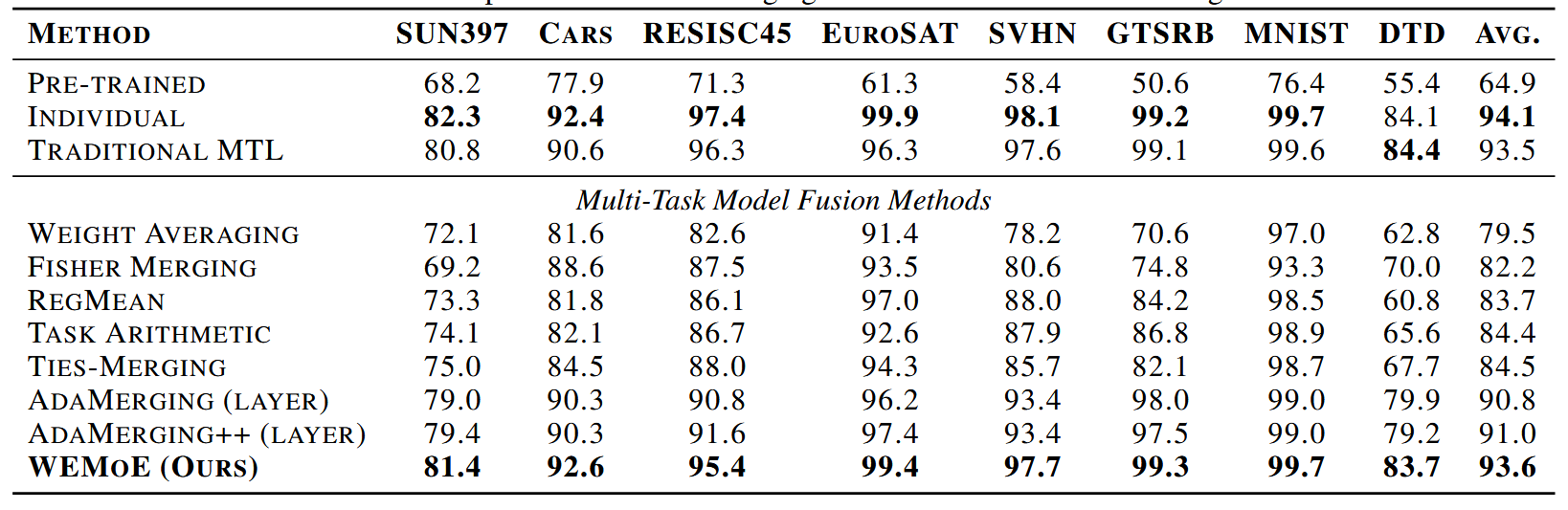
Tab.3:在8个任务上merge CLIP-ViT-L/14模型时的多任务性能。
1.3.2.2 收敛性和灵敏度对比
如图所示,$Fig.4$展示了不同步数的merge后的WEMoE的性能。在$Fig.4(a)$中,这篇文章merge了用不同学习率配置的CLIP-ViT-B/32模型。可以观察到,随着训练步数的增加merge模型的性能呈现上升趋势,且收敛的很快,在仅仅200轮就达到了一个很高的准确率。此外,不同学习率的影响并不显著,说明文章提出的方法对学习率参数并不敏感。这是一个好的性质,因为它降低了对超参调整的需求。
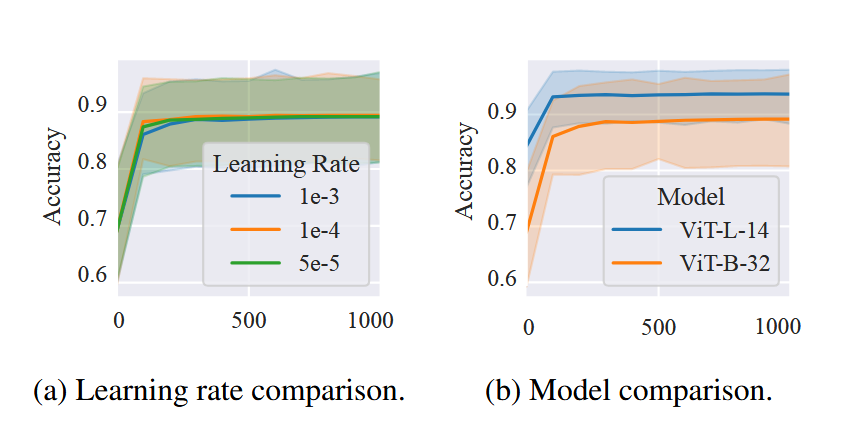
Fig.4:不同步数的merge模型的性能。
(a):不同学习率的CLIP-ViT-B/32模型
(b):CLIP-ViT-B/32和CLIP-ViT-L/14的比较
1.3.2.3 扩大规模策略的消融实验
为了深入调查扩大规模策略的影响,文章在CLIP-ViT-B/32上做了实验,对比了三种不同的扩大规模策略:(1)整个Transformer块:扩大规模的MoE被应用在整个Transformer块。(2)Attention+MLP:扩大规模的MoE被分别应用在attention权重上和MLP权重。(3)仅MLP:扩大规模的MoE仅用在MLP权重上,即这篇文章提出的最终框架,见上图概览。这三种的实验比较结果如下表所示:
可以看到,当注意力和MLP权重分别增加时,大多数任务的性能都得到了显著提高,超过了其他两种方法,但是如果路由网络同时应用于MLPs和attention权重,则会导致计算负载和内存使用量增加,边际性能增益可能无法保证成本,所以文章最后选择了只将扩大规模的MoE应用在MLP权重上。
1.3.2.4 泛化能力和鲁棒性评估
泛化能力评估:文章实验从八个下游任务中选择了两个任务作为看不见的任务,在剩余的六个任务上使用了微调后的模型进行merge,构建了一个六任务模型。然后将这个六任务模型应用于看不见的任务,以评估模型的泛化能力。文章在0层路由和2层路由上都做了实验,结果如下表所示:
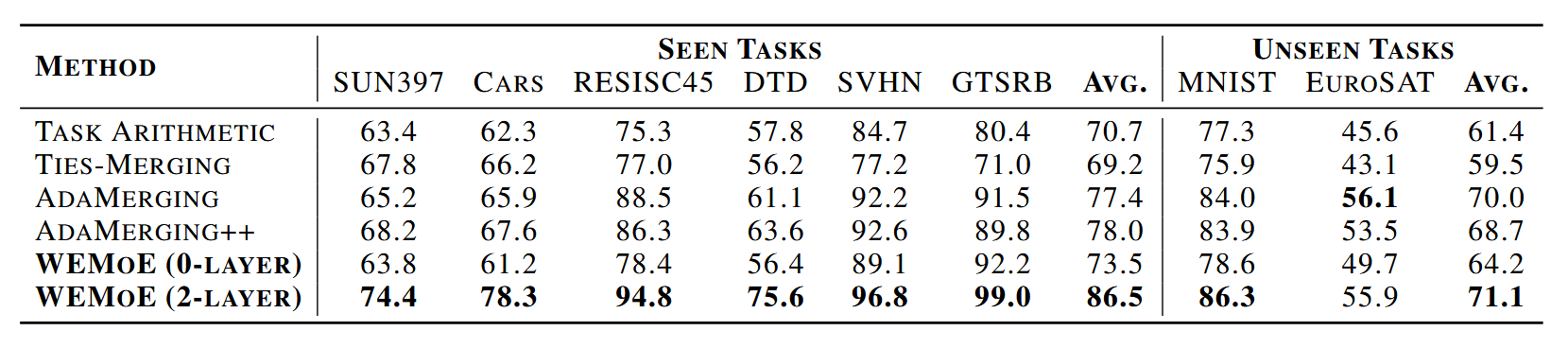
鲁棒性评估:文章实验利用(Hendrycks&Dietterich,2019)中建议的方法从干净的测试集中生成失真的图像,选择了七种类型的失真,实验结果如下:
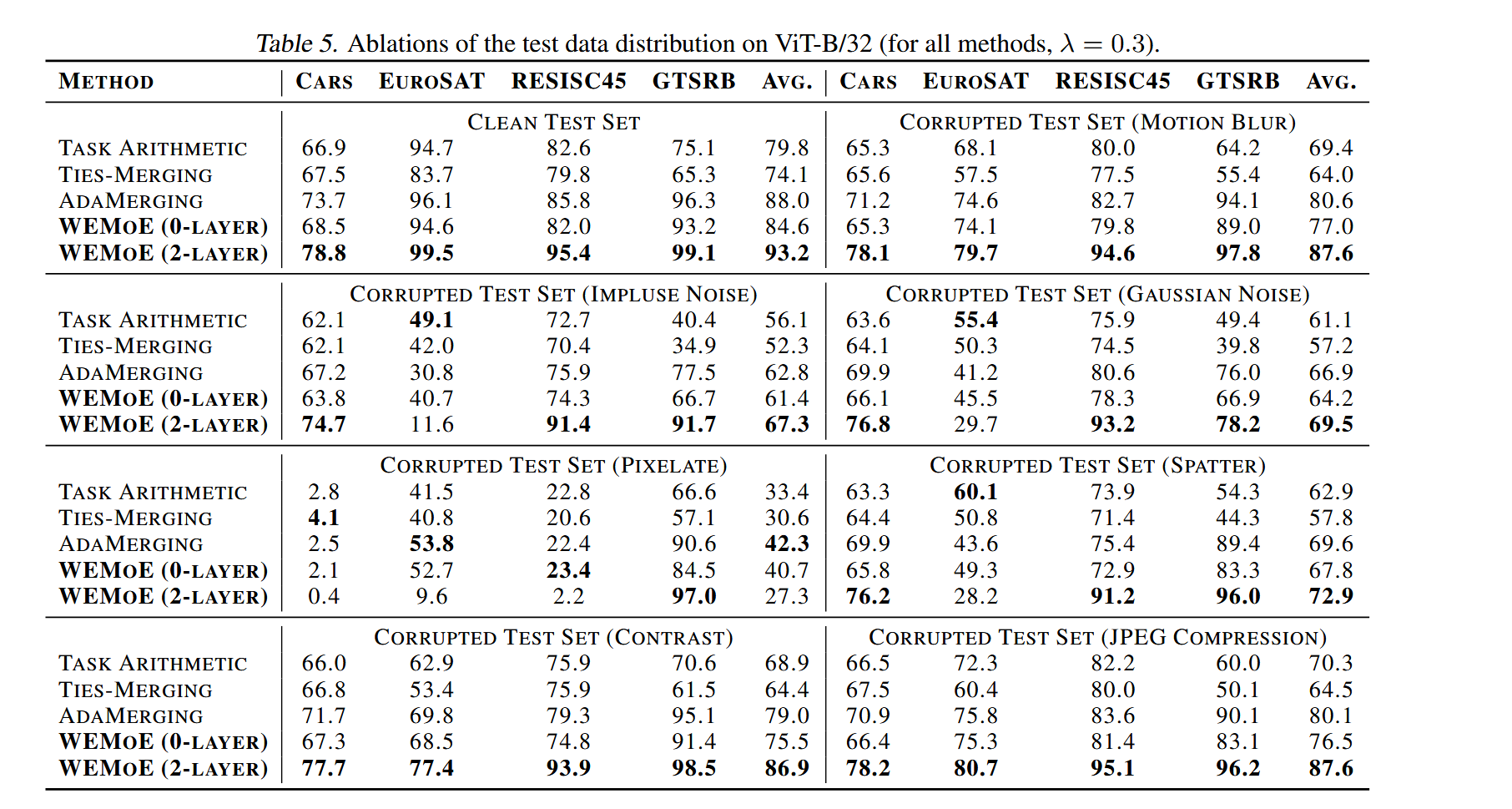
实验结果表明,在各种方法中,WEMoE($l=2$)在干净的测试集和大多数失真的测试集上始终达到最高性能。这表明文章提出的方法在处理干净和失真的数据方面都是有效的。然而,在图像质量显著下降的情况下,如pixelate像素化,WEMoE($l=2$)可能会过拟合某些特定任务,导致性能下降。 相比之下,WEMoE($l=0$)在这种条件下往往表现出更稳定的性能。这归因于其较低的参数数量,使其不易过拟合。
观察下图,可以发现merge模型的性能相对于任务向量的缩放系数$\lambda$相对稳定,这表明文章提出的方法对任务向量的缩放系数$\lambda$也更具鲁棒性。
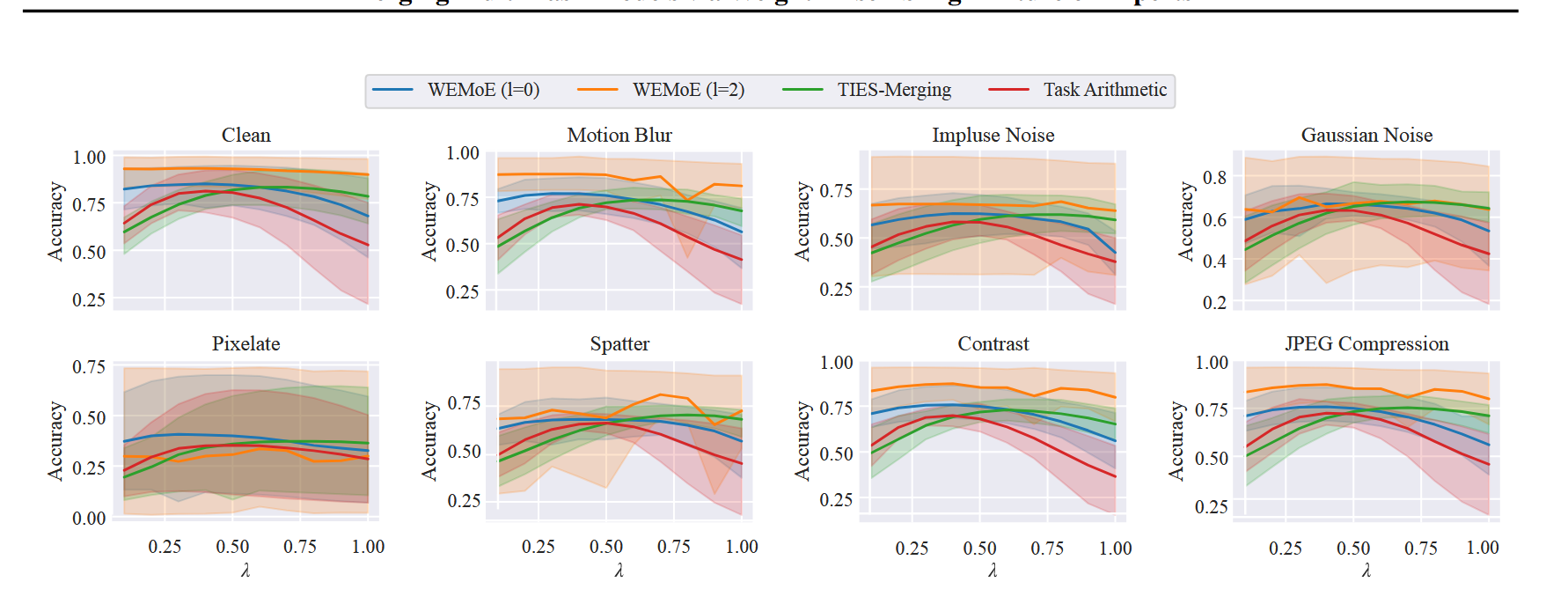
1.4 总结
文章提出了一种新的方法来merge来自不同任务的基于Transformer的视觉模型,且文章提出的方法在从各种特定任务的微调模型中转移知识并构建统一的多任务模型方面是有效的;提出了一种新的WEMoE模块,该模块可以根据输入样本动态集成共享和特定任务的知识;进行了广泛的实验,实验结果证明了方法的有效性。
1.5 问题与思考
1.5.1 他的模型外推怎么做的,为什么能提升泛化能力?
猜测:
架构图中的Router可单选可多选,如果input是$\tau_1$的,Router准确的话应该只会选择$\tau_1$,此时$\theta=\theta_0+\lambda\tau_1$,这样就保证了在单个任务上的损失很小,然后对于没见过的任务猜测是follow的task arithmetic那篇的任务类比,应该是利用任务类比的思想将几个task vector进行组合来提高在另一个task上的性能,导致了他这个模型可以做到模型外推提高泛化能力,究竟是不是利用task vector进行组合做模型外推也要看下他代码咋写的。
1.5.2 他的消融实验怎么做的?

主要是做了三种方案的比较,最后综合选择了只替换MLP的方案,因为如果路由网络同时应用于MLPs和attention权重,则会导致计算负载和内存使用量增加,边际性能增益可能无法保证成本,所以综合考虑用了只替换MLP的方案。
1.5.3 这篇工作解决了什么问题?怎么解决的?如何讲story?怎么通过实验论证的?
解决的问题:提供了一种更灵活的方案可以适应每个实例的特定需求。
解决方案:提出了WEMoE来进行解决。
如何讲story:先讲当前现有merge方法不够灵活,最优解决方案可能会因为输入而变化,然后提出自己的方案说自己的方案更能灵活处理,然后做实验比较SOTA和自己的方法的性能,再比较模型的泛化能力和鲁棒性。
1.5.4 我认为这篇工作还存在什么不足?
暂时没想到,非要说不足我觉得那个数学表达式可以参照AdaMerging的思想对不同的任务向量给予不同的权重值$\lambda_i$,就是变成$\theta^{MLP}=\theta_0^{MLP}+\sum \lambda_i \tau_i$这种形式,这样就是对于在看不见的任务上可以用现有的几种任务的task vector给他们不同的权重去进行组合,感觉会更加灵活,泛化能力会更好。
2. 基础知识
2.1 MLP
MLP(Multilayer Perceptron,多层感知机)是一种经典的神经网络架构,广泛应用于各种机器学习任务,如分类、回归和特征学习。
2.2 对预训练模型上分别对不同任务进行微调得到一系列微调好的模型
第2页原文:
we finetune the pre-trained model f individually for each task si, resulting in a series of fine-tuned models
对同一个预训练模型对不同任务微调有两种结果:
- 如果是将不同任务的数据综合在一起给预训练模型进行微调得到的就是综合这些任务能力的一个微调模型。
- 如果是将不同任务的数据分别进行微调得到的就是一系列对应不同任务能力的微调模型。例如对QWen的一个预训练模型对不同任务进行微调会得到Code能力的微调模型、math能力的微调模型等。
2.3 Pareto前沿
Pareto前沿(Pareto Front)是多目标优化问题中的一个重要概念,用于描述在多个目标之间无法进一步改进的最优解集合。在许多实际问题中,我们通常需要同时优化多个目标,而这些目标之间往往是相互冲突的。这些目标之间很难同时达到最优,因此需要找到一种平衡。在多目标优化问题中,一个解被称为Pareto最优解(Pareto Optimal Solution),如果不存在另一个解能够在不恶化至少一个目标的情况下改善至少一个目标。换句话说,Pareto最优解是无法在不牺牲其他目标的情况下进一步改进的解。Pareto前沿(Pareto Front)是所有Pareto最优解的集合。它是一个高维空间中的边界,表示在多个目标之间达到最佳平衡的解。
2.4 $arg \min_\theta\sum_{i=1}^n\mathcal L_i(\theta)$
调整参数$\theta$使得损失函数的加和最小。
2.5 auxiliary task
辅助任务(auxiliary task) 是指在训练过程中,为了帮助模型更好地学习而引入的额外任务。这些任务通常与主要任务相关,但不是最终目标。辅助任务可以帮助模型学习更有用的特征表示,从而提高模型在主要任务上的性能。
目标任务(target task) 是模型最终需要解决的任务,也是评估模型性能的主要标准。这是模型的主要目标,通常是我们最关心的任务。
控制任务(control task) 是指用于评估模型性能的辅助任务,通常用于验证模型在不同条件下的泛化能力。控制任务可以帮助我们更好地理解模型的行为,特别是在目标任务数据有限或不完整的情况下。
2.6 domain gap
图像及点云的标注的一件非常耗时、无聊、繁琐的事情。人工标注的成本高、耗时长,因此人们会用计算机合成的图像数据集进行语义分割模型的训练。合成的数据集称为 source domain(源域),真实世界的数据集称为target domain(目标域)。
通常我们会使用源域中的数据进行训练模型,然后将在目标域进行分割预测时往往会产生很多错误的标签,称为伪标签噪声。
由于不同的数据集之间的目标分布不同,即源域和目标域之间存在域差距——Domain Gap 导致这种现象产生。
2.7 dictionary learning
Dictionary Learning(字典学习)是一种无监督学习方法,主要用于从数据中学习一组称为“字典”的基向量(或原子),并用这些基向量的线性组合来表示数据。它在信号处理、图像处理、机器学习和数据压缩等领域有广泛应用。
2.8 ReLU
激活函数是指在多层神经网络中,上层神经元的输出和下层神经元的输入存在一个函数关系,这个函数就是激活函数。如下图所示,上层神经元通过加权求和,得到输出值,然后被作用一个激活函数,得到下一层的输入值。引入激活函数的目的是为了增加神经网络的非线性拟合能力。
ReLu,全称是Rectified Linear Unit,中文名称是线性整流函数,是在神经网络中常用的激活函数。通常意义下,其指代数学中的斜坡函数,即 。其对应的函数图像如下所示:
2.9 top-1 accuracy
top-1:就是你预测的label取最后概率向量里面最大的那一个作为预测结果,如果你的预测结果中概率最大的那个分类正确,则预测正确。否则预测错误
top-5:就是最后概率向量最大的前五名中,只要出现了正确概率即为预测正确。否则预测错误。
由此可以看出,top5一般比top1大。
2.10 MLP
多层感知机,主要是利用隐藏层和激活函数来进行非线性变换($Wx+b$)得到一个非线性模型,常用激活函数有Sigmoid,Tanh,ReLU,使用Softmax来处理多类分类,超参数为隐藏层数和隐藏层大小。