
Model Merging in Pre-training of Large Language Models
摘要
模型merge已成为增强大型语言模型的一种有前景的技术,尽管它在大规模预训练中的应用仍然相对未被探索。本文对预训练过程中的模型merge技术进行了全面的研究。通过对从数百万到超过1000亿个参数的密集和混合专家(MoE)架构的广泛实验,我们证明,merge以恒定学习率训练的检查点不仅可以显著提高性能,还可以准确预测退火行为。这些改进不仅提高了模型开发的效率,还显著降低了培训成本。我们对合并策略和超参数的详细消融研究为潜在机制提供了新的见解,同时揭示了新的应用。通过全面的实验分析,我们为有效的模型合并提供了开源社区实用的预训练指南。
1. 引言
现代大型语言模型已经证明了其卓越的能力,在各种任务中得到了广泛的应用。尽管LLM在基本任务中表现出色,但仍然面临着几个关键挑战,包括广泛的预培训成本、特定领域后培训的低效性、不可精确预测的性能扩展以及大规模培训的不稳定性。模型merge作为一个相对年轻的话题,为缓解这些实际挑战提供了一种有前景的方法。
最近,模型merge的好处主要在后训练阶段进行了研究,在这个阶段,几个针对不同下游任务进行微调的模型被组合成一个单一但更通用的模型。例如,使用DARE方法将WizardLM与WizardMath合并,可以显著提高GSM8K的性能,使其得分从2.2提高到66.3。相比之下,关于预训练阶段模型合并的研究仍然很少。这种预训练合并通常涉及组合来自单个训练轨迹的检查点,如LAWA所探索的,该LAWA利用模型合并来加速LLM训练。然而,随着模型和数据的急剧扩展,独立研究人员很难评估模型合并对大规模模型的影响,这主要是由于从广泛的预训练中获得中间检查点的机会有限。尽管DeepSeek和LLaMA-3都表示他们采用了模型合并技术进行模型开发,但关于这些技术的详细信息尚未公开披露。
在这项工作中,我们主要关注预训练阶段的模型合并,提出了预训练模型平均(PMA),这是一种在预训练阶段进行模型级权重合并的新策略。为了全面评估PMA,我们从头开始训练了一组不同大小和架构的LLM,包括参数范围从411M到70B的Dense模型,以及激活/总参数范围从0.7B/7B到20B/200B的混合专家(MoE)架构。我们首先研究了PMA的性能影响,并在预热稳定衰减(WSD)学习计划的不同阶段建立了系统评估,该计划最近成为LLM预训练的lr调度器的流行选择。实验结果表明,在稳定训练阶段进行模型合并,可以在不同训练步骤中获得一致的性能增益。更值得注意的是,在余弦衰减阶段的早期应用PMA通常会获得与最终阶段退火相当甚至更优的性能。这些发现表明,在具有常量$lr$的漫长预训练阶段,PMA可以作为退火性能的快速、可靠但低成本的模拟器,实现更快的验证周期和显著的计算节省。
在我们的PMA框架的基础上,我们首先使用各种流行的merge策略来评估其性能,包括简单移动平均(SMA)、加权移动平均(WMA)和指数移动平均(EMA)。值得注意的是,我们的实验表明,这些方法之间的性能差异逐渐变得可以忽略不计。我们进一步研究了PMA的这些重要因素,即每个merge checkpoint之间的间隔、merge中涉及的模型数量和模型大小,将如何影响合并性能。我们的分析揭示了两个重要发现:第一,最优合并区间与模型大小具有明显的比例关系。其次,在合并过程中加入更多检查点,可以在训练完成后持续提高性能。
此外,我们还研究了PMA是否可以为连续的持续训练(CT)或监督微调(SFT)阶段产生更有效的初始化权重,以提高下游模型的性能。我们实际观察到,与通常使用最新可用检查点初始化这些阶段相比,使用PMA进入CT和SFT阶段可以产生更平滑的GradNorm曲线,从而有助于稳定训练动态,而不会损害性能。这一发现激发了模型合并在训练稳定中的新应用,我们称之为PMA-init。我们证明,在LLM训练经历严重不可恢复的损失尖峰和训练动态中断的情况下,在N个先前检查点上应用PMA-init来恢复训练,可以从不稳定的训练轨迹中可靠地恢复。
总之,我们的论文做出了以下主要贡献:
- 我们提出了预训练模型平均(PMA)策略,这是一种在LLM预训练期间进行模型合并的新框架。通过跨模型尺度(从数百万到超过100B个参数)的广泛实验,我们证明,merge稳定训练阶段的检查点可以产生一致且显著的性能改进。
- 我们深入研究了用于权重初始化的模型合并(PMA-init)的新应用,以帮助稳定训练过程,而不会损害下游性能,特别是当它遭受不可恢复的损失尖峰和破碎的训练动态时。通过广泛的实验,我们证明了PMA-init在CT和SFT阶段的有效性。
- 我们还全面消除了各种模型合并技术及其相关的超参数。我们的研究结果为研究界提供了实用的预训练指南,并有效地进行了模型合并。然而,PMA的低成本和快速部署也使其成为预训练过程的可靠和经济的监测器,可以灵活地模拟退火后的最终模型性能。
2. 文章工作及思考
2.1 背景、动机及挑战
背景和动机:现代大型语言模型已经证明了其卓越的能力,在各种任务中得到了广泛的应用。尽管LLM在基本任务中表现出色,但仍然面临着几个关键挑战,包括广泛的预培训成本、特定领域后培训的低效性、不可精确预测的性能扩展以及大规模培训的不稳定性。模型merge作为一个相对年轻的话题,为缓解这些实际挑战提供了一种有前景的方法,但是目前关于预训练阶段模型合并的研究仍然很少。
挑战点:随着模型和数据的急剧扩展,独立研究人员很难评估模型合并对大规模模型的影响,这主要是由于从广泛的预训练中获得中间checkpoint的机会有限。且虽然DeepSeek和LLaMA-3都表示他们采用了模型merge技术进行模型开发,但关于这些技术的详细信息尚未公开披露。
2.2 工作内容
- 提出了PMA(Pre-trained Model Average)方法来应对预训练阶段模型merge的挑战,PMA是一种在预训练阶段进行模型级权重合并的新策略。做了大量实验证明了merge稳定训练阶段的检查点可以产生一致且显著的性能改进。
- 提出了用PMA-init进行权重初始化,通过大量实验证明了PMA-init在CT和SFT阶段的有效性。
- 全面消除了各种模型merge技术及其相关的超参数,使其可以低成本快速部署。
2.3 QA
2.3.1 模型merge对模型性能有何影响?
文章在模型预训练过程中采用了预热-稳定-衰减(WSD)策略,结合了恒定学习率和随后的余弦衰减阶段,并在这两个阶段都做了实验探索模型merge的效果。
实验发现,在恒定学习率阶段,merge后的模型在多个下游任务中都有明显的性能提升,如图所示:
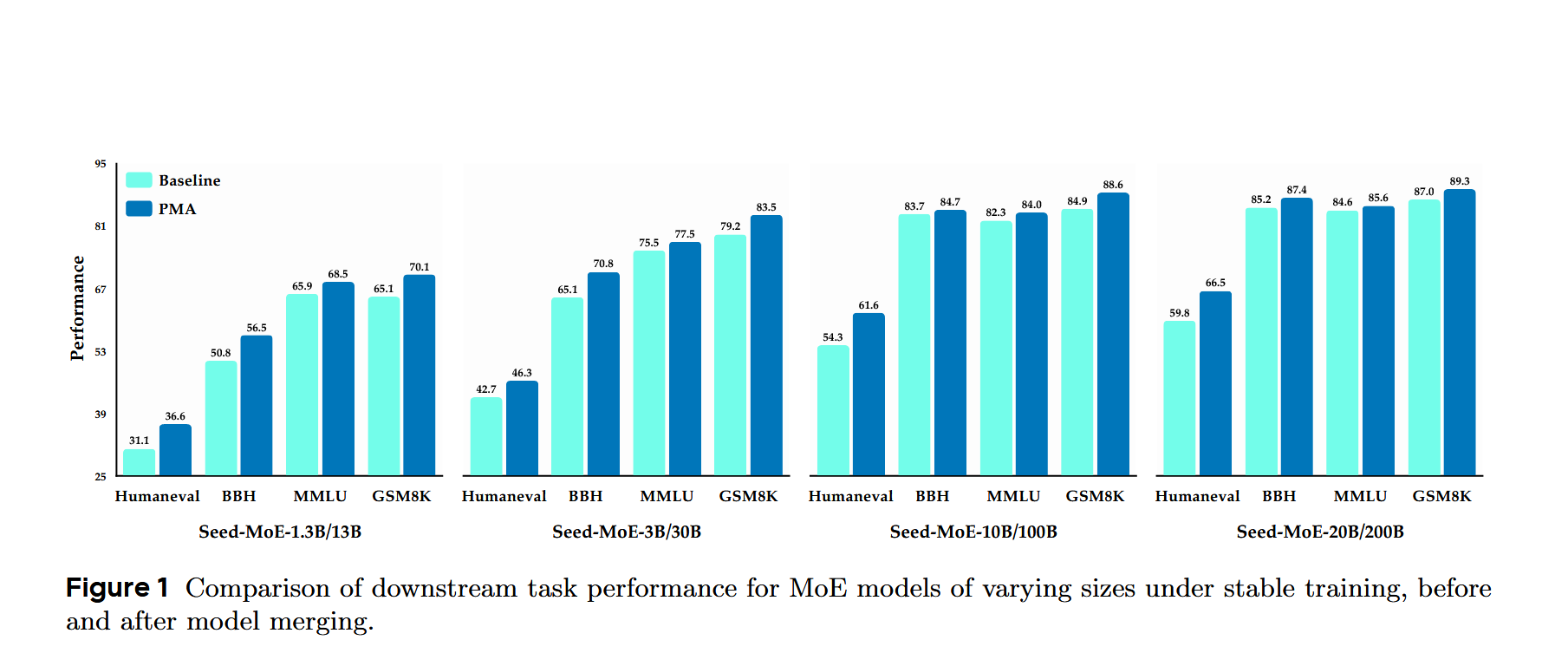
在余弦退火阶段进行merge后,随着学习率逐渐降低,模型稳步收敛,性能持续提高,在PMA退火早期和结束时性能相当,如图所示:
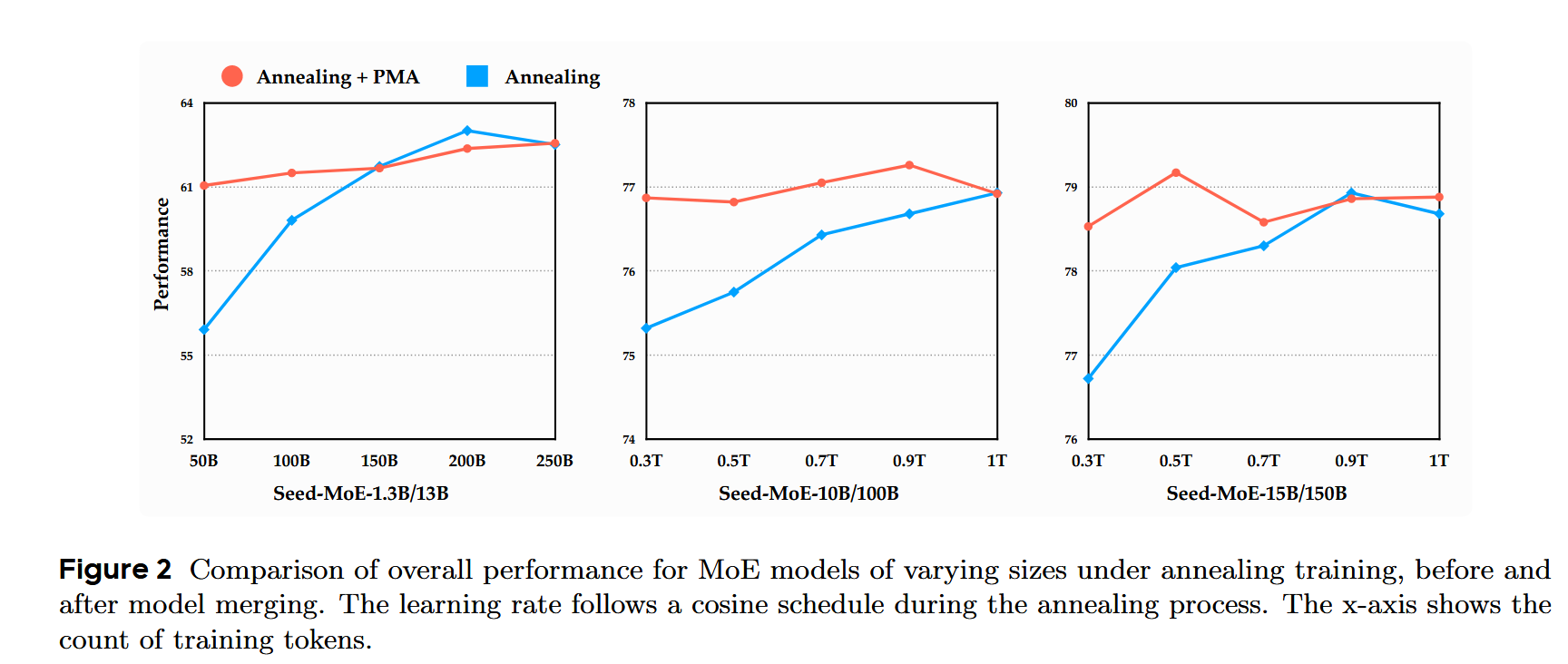
因此,文章认为模型merge有效,且可以只用预热-稳定阶段和PMA,跳过衰减阶段避免学习率的调整;使用恒定学习率进行预训练并结合模型merge,可以在训练过程中的任何阶段有效匹配退火模型的性能,而不需要学习率退火。这种方法可以加快验证速度同时减少计算资源。
2.3.2 不同模型merge方法对最终性能的影响?
文章主要比较了SMA、WMA、EMA三种方法的性能:
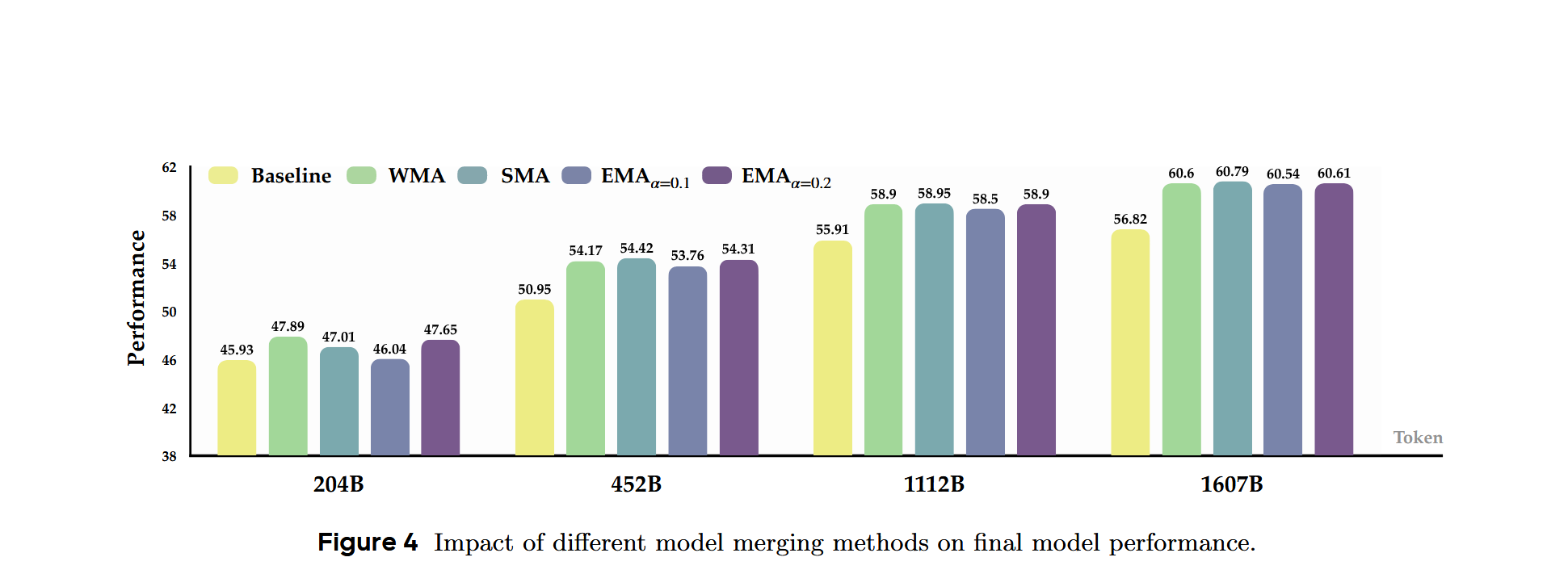
考虑到简便性和稳定性,文章最后用的是SMA。
2.3.3 如何确定模型的最佳merge区间和权重数?
主要是做实验发现的,实验发现最佳间隔随着模型规模的增大而增大,实验结果:
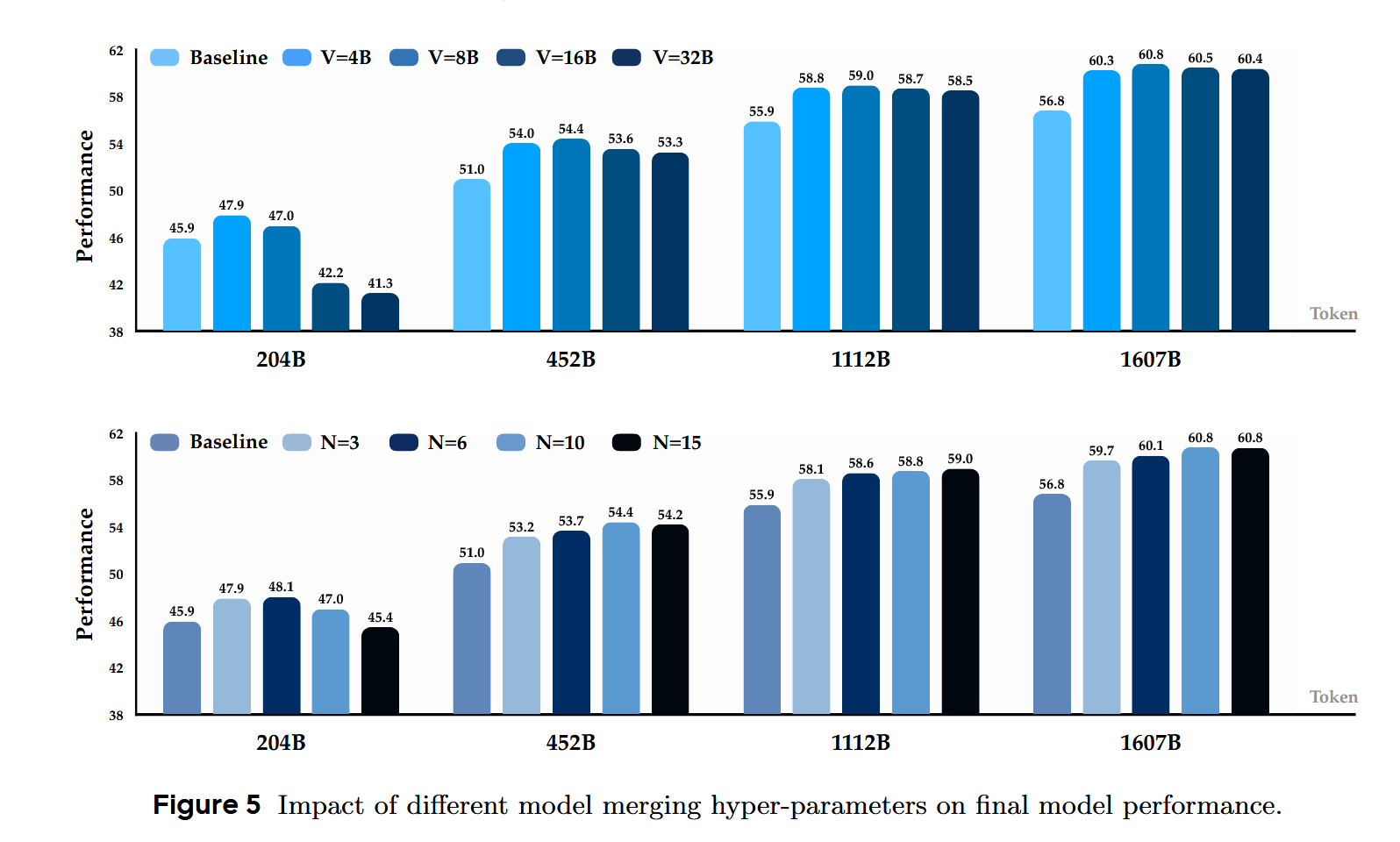
<font color="red">问题:为什么204B的时候16B和32B的效果差那么多,为什么说间隔大的时候初始训练阶段受不稳定权重影响大?</font>
This is likely because large intervals incorporated unstable weights from the initial training phase, leading to significant weight disparities and suboptimal outcomes.
2.3.4 merge预训练模型是否有助于下游训练?
文章用PMA(PMA-init)初始化了下游训练,主要研究了在CT阶段和SFT阶段的效果。
CT阶段:做了消融实验,评估了CT阶段的PMA-init在不同学习率计划下的灵敏度。实验发现,使用PMA的模型在训练结束时可以收敛到和baseline差不多的性能水平,同时PMA-init不需要进行广泛的学习率调整。
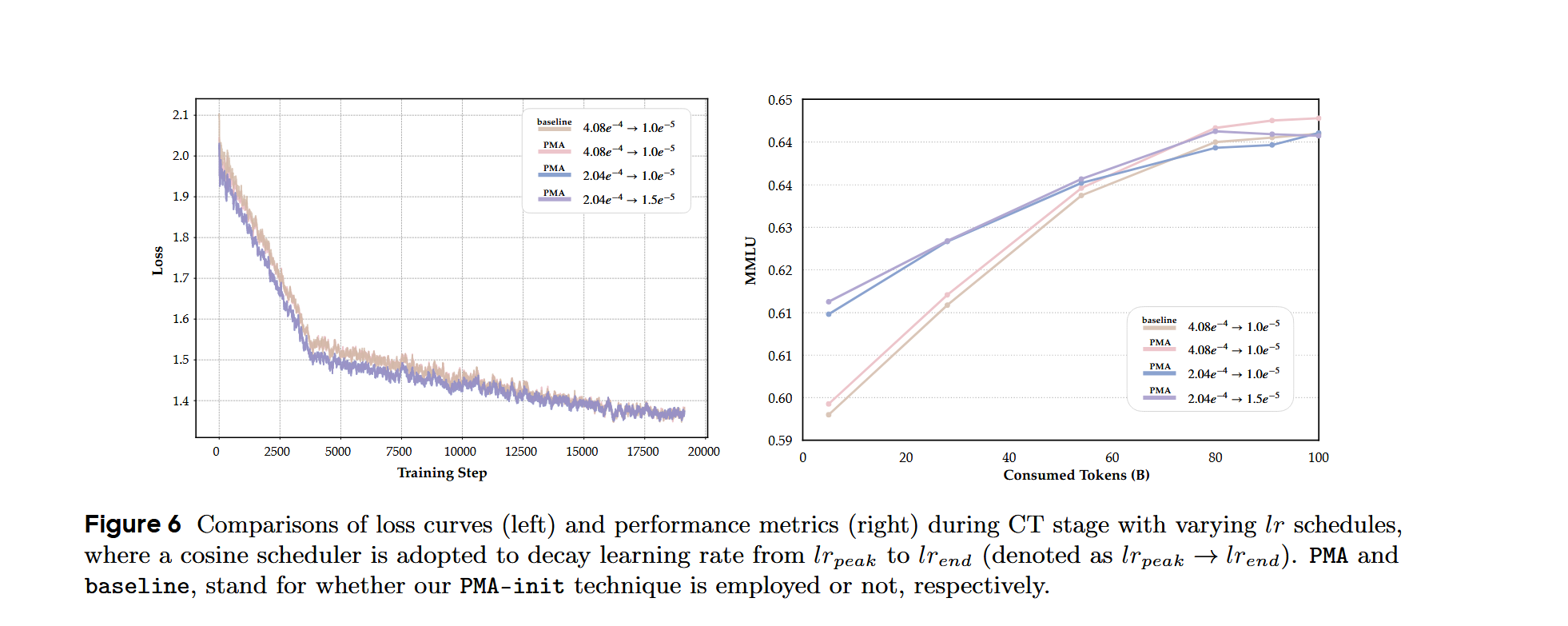
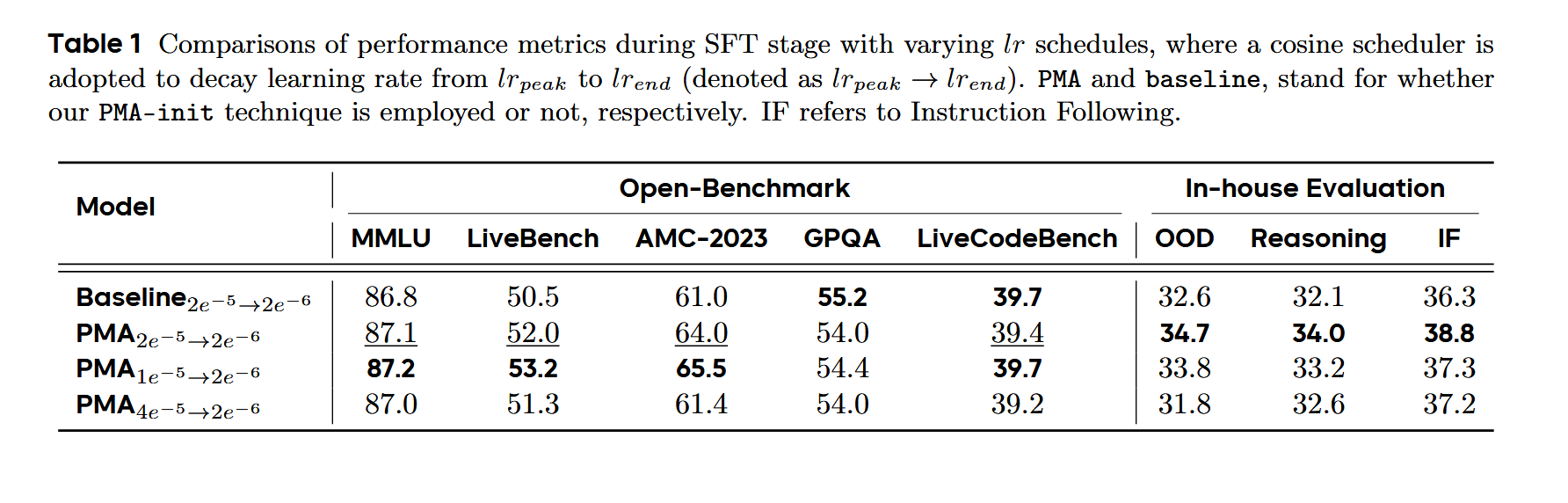
SFT阶段:实验发现,PMA的性能优于baseline。
2.4 消融实验
就是2.3.4的CT阶段和SFT阶段做的实验。
2.5 思考
2.5.1 文章脉络,怎么讲的story?怎么做的实验?
讲背景和动机->提出自己的方法->做实验论证自己的方法有效果。
实验方面主要是对比其他merge方法去进行横向对比,对PMA-init,去做了该初始化后对下游任务的效果进行实验对比,然后比较了PMA和baseline在不同规模模型下的效果。
2.5.2 PMA?
PMA 就是在预训练过程中,定期将不同训练阶段的模型权重进行平均,生成一个「merge模型」。这是因为:预训练后期的模型权重往往在参数空间中探索了不同的局部最优解,通过平均化可以抵消单个模型的偏差,逼近更优的全局解。
2.5.3 不足?
3. 总结
文章提出这项研究开创了在大规模模型具有挑战性的预训练阶段对模型合并进行更深入探索的先河。通过训练一系列MoE和Dense模型并执行严格的消融,研究发现,merge稳定训练阶段的checkpoint不仅可以显著提高性能并预测退火,还可以简化开发并降低成本。
2. 基础知识
2.1 时间序列预测基本方法
(77 封私信 / 80 条消息) 时间序列预测基本方法–移动平均(SMA、EMA、WMA) - 知乎
2.2 GradNorm
多任务学习中动态调整loss的$w$的算法。
2.3 模型退火阶段
2.4 Warmup-Stable-Decay(WSD)
预热-稳定-衰减
2.5 Learning Rate Scheduler(LRS)
学习率调度器
(77 封私信 / 80 条消息) 论文笔记_MiniCPM:揭示小型语言模型在可扩展训练策略下的潜力 - 知乎